 in Sweden from 7 - 8 October 2025. Pre-book a meeting to connect with our
product experts.
in Sweden from 7 - 8 October 2025. Pre-book a meeting to connect with our
product experts.



The part retailers only discover after two or three cycles of “We can build this ourselves.”
Every few months, we meet a retail team that proudly announces it is building its own personalization engine.
We never try to talk them out of it.
Because honestly? In 2025(or 2026, now that we’re inching closer to that), it feels like something you should be able to build.
You have embeddings.
You have vector databases.
You have open-source models that can map product similarities with ridiculous ease.
You have the talent.
So someone on the engineering team says the magic sentence: “Let’s build our own recommender.”
Everyone nods. Makes sense. Because on the surface, personalization looks straightforward: take products, find patterns, rank them, serve them up.
Then six months later (maybe after a Black Friday meltdown), it hits you.

You didn’t build a product recommendation feature. You accidentally took on responsibility for an entire real-time decisioning ecosystem.
And ecosystems don’t behave like features. They’re more like living things. They grow. They mutate. They break at 3am. And they demand constant attention.
This is the part no one sees coming.
Personalization isn’t a model. It’s fifteen interconnected systems pretending to be one.
The biggest misunderstanding in retail tech? Thinking that personalization = “the model.”
But the real work is everything underneath it. And you don’t see that until it becomes your full-time job.
Let me paint the picture.
A European fashion retailer built their first internal model – simple “similar items” stuff. It worked beautifully on the product page. Sales went up. Click-through rates improved. The UX was clean. The data science team got high-fives.
Then merchandising asked: “Can we dial down discounted products when we’re launching new collections?”
Now you need business rules.
Marketing chimed in: “Can we show brand-focused looks to new visitors, but personalized picks to returning customers?”
Now you need context switching.
Operations joined the party: “We need to avoid recommending out-of-stock items during peak season…” Now you need real-time inventory feeds

None of this sounds crazy. This is just retail. But each request chips away at your simple system–until that original “similar items” model is doing maybe 5% of the actual work.
That’s when it hits you: the hard part isn’t the model. It’s everything around it.
Where most internal systems break: decision debt
You know technical debt. We all do.
But personalization has a nastier cousin: decision debt.
Decision debt is what happens when you take shortcuts early on because you’re trying to ship fast.
You don’t add real-time inference at first – it’s too slow to implement.
You hardcode boosts instead of building a rules engine.
You reuse one strategy across all categories because it’s “good enough for now.”
You ignore long-tail items because the uplift seems marginal.
You skip building a proper evaluation framework because A/B testing can come later.
Each of these feels harmless in the moment.
But here’s the problem: decision debt compounds. Fast.
Every time the business changes– new categories, new collections, new seasonal patterns, new user behavior, and new merchandising tactics– that debt gets worse.
We worked with a North American electronics retailer who built a solid internal product recommender. First 90 days? Looked great. Simple. Fast. Effective.
Then they launched a new product line of “PC Gaming Accessories,” and everything fell apart.
Strategies that worked for TVs didn’t work for keyboards. Bundling logic for phones didn’t translate to gaming components. Their internal system had no concept of category-level strategy orchestration, and their team spent the next four months adding exceptions on top of existing exceptions.
Decision debt sneaks up on you.
Then one day, it buries your roadmap.
The Plateau no one predicts
Let’s say you avoid all the traps. You don’t take shortcuts. You build clean. Your team ships a solid product recommendation engine with no decision debt.
You should be good, right?
Here’s the thing: even well-built internal systems hit a ceiling. Not because of messy code or technical debt, but because of algorithmic limitations.
The models that give you early wins? They max out. Fast.
Similarity models work great at first. Someone’s looking at black dresses, you show more black dresses –boom, conversion. But similarity can’t tell you when someone’s ready to explore a new style, or when they’re gift shopping for someone else, or when they’ve already bought three black dresses and need something different.
Popularity models perform well initially. Top sellers are top sellers for a reason. But popularity can’t adapt to individual taste, can’t predict what someone might love before they know they love it, and definitely can’t help with discovery beyond what’s already trending.
Cross-sell works for obvious pairings. Chargers with phones. But it struggles with nuanced bundles, can’t optimize for margin, and misses opportunities for introducing customers to new categories.
These aren’t bad strategies. They’re just limited. And once you’ve captured all the obvious behavior, the gains start flattening out.
Here’s what the performance curve actually looks like:
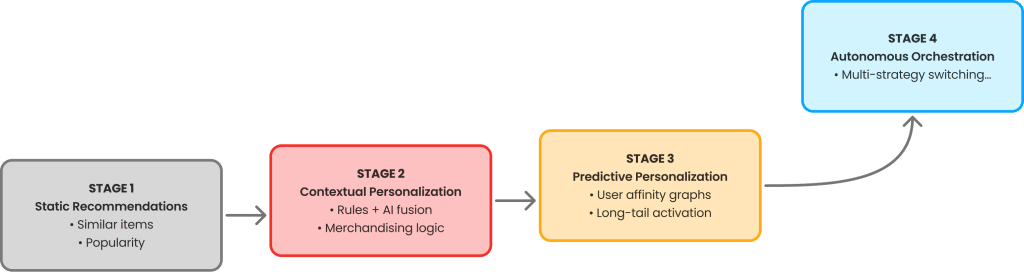
Stage 1 strategies (similarity, popularity, basic cross-sell) can be incredibly effective early on. They capture high-intent, obvious behavior really well. But they tap out around 60-120 days because they’re reactive, not predictive. They show what people already want, not what they might want.
Moving to Stage 2 (contextual) or Stage 3 (predictive) personalization requires fundamentally different approaches. You need models that understand:
- Session intent vs long-term affinity
- Category exploration patterns
- Seasonal timing and freshness
- Margin optimization alongside relevance
- Individual discovery thresholds
And that’s not just “adding more data to your existing model.” It’s building entirely new strategies.
The plateau shows up quietly. Your metrics don’t crash. They just stop improving. AOV stalls. Category penetration flatlines. New product discovery doesn’t move.
Not a sharp drop. A soft ceiling.
So what does it take to break through that ceiling?
The Personalization Ecosystem (what you accidentally signed up for)
Here’s what you’re really on the hook for when you build in-house:

You don’t see this stuff when you’re building that first model. You only see it when the business starts asking for things your system was never designed to handle.
And if any of these layers are missing? Personalization breaks. Not in obvious ways– subtly. Performance slowly erodes. AOV stalls. Long-tail products don’t move. Seasonal launches underperform. Customers stop discovering new stuff.
The teams that win don’t choose “Build” or “Buy.” They blend.
The retailers crushing it right now aren’t building everything themselves. And they’re not outsourcing everything either.
They’re doing something smarter:
They build what makes them unique. They buy what makes them fast.
They build: brand experience, UI, customer journeys, bundling logic, promotions, storytelling.
They buy: the machinery underneath–orchestration, data freshness, affinity modeling, margin awareness, strategy switching, failure recovery, all the messy infrastructure that never ends.
This approach gives them speed and differentiation.
More importantly? It keeps their engineering and data teams focused on work that actually moves revenue–not maintaining pipes.
The real question retailers should ask
It’s not: “Can we build a product recommendation system?”
You can. Every retailer can. That’s not the debate anymore.
The real question is:
“Can we build and sustain a full personalization ecosystem faster and better than a platform that has already solved this across hundreds of retailers?”
That’s the inflection point.
It’s why retailers like Matas, Blue Tomato, and even large global multi-category brands eventually turned to Algonomy Recommend™ .
Not because they couldn’t build it. They absolutely could.
But because they realized Recommend™ isn’t just “a model.”
It’s a retail-native decisioning system that already knows how to blend user affinity, business rules, inventory reality, margin constraints, and real-time context into every single product recommendation.
That’s what drives the lift. Not the algorithm. The ecosystem around it.
Look, the smartest retailers aren’t choosing between build or buy.
They’re choosing speed.
They’re choosing focus.
They’re choosing to build what makes them different– and plug into what makes them faster.
That’s the quiet truth behind personalization success.
And it’s exactly what Algonomy Recommend™ was built to deliver.





