Ascend: Our product roadmap webinar is back! Hear from our product leaders on how the latest updates unlock more value for you. Register for Free →
Ascend: Our product roadmap webinar is back! Hear from our product leaders on how the latest updates unlock more value for you. Register for Free →
Supply Chain, Merchandising
Despite having abundant data from multiple functions, retailers often struggle to make effective data-driven decisions. The prevalence of sparse and noisy data, one of the major reasons behind this, significantly challenges retail planning by distorting demand forecasts and making accurate decision-making difficult.
Consequently, retailers risk over- or under-stocking, missing sales opportunities, and managing inventory inefficiently—ultimately impacting profitability and customer satisfaction. Navigating this complexity is crucial for precise, data-driven planning.
Sparse data means insufficient data and can be due to low sales volumes, infrequent customer interactions, or missing data points. For instance, a retailer may have sales data for only a few products or stores, or there may be gaps in customer behavior tracking.
Sparse data makes it challenging to draw meaningful conclusions, as there aren’t enough data points to detect patterns or trends.
Examples of sparse data in retail:
Noisy Data refers to data that contains a lot of irrelevant or erroneous information, which can obscure the true patterns or signals that are important for decision-making. Noise can be caused by data entry errors or outliers that don’t reflect typical behavior.
Some examples include:
To mitigate the impact of noisy and sparse data, different software solutions leverage different techniques, such as removing or correcting noise by data cleaning or enhancing sparse data by adding extra data, or data augmentation.
This affects the overall quality of forecasts which can snowball into stockouts or overstock situations owing to flawed modeling data, inaccurate sales predictions, impacting budgeting and financial planning, and more.
Advanced data visualization and modeling techniques, such as demand forecasting require time series modeling in most cases. In this class of modeling, it is not possible to omit the data points that are missing or identified as an outlier (noisy data points).
Moreover, since the option of randomly selecting the training and testing data is not available in time-bound data, entire testing data can easily become a sequence of noisy data.
Order Right (OR) has a hierarchical forecasting framework that effectively handles noise and sparse data found at highly granular levels, such as the product-store level.
Every retail product has a hierarchy, such as category, sub-category, and so on. As we move up in a product hierarchy, such as category, or sub-category level from the SKU level, the data becomes more stable and less sparse. This is where the OR modeling typically starts, and is termed as the Anchor level.
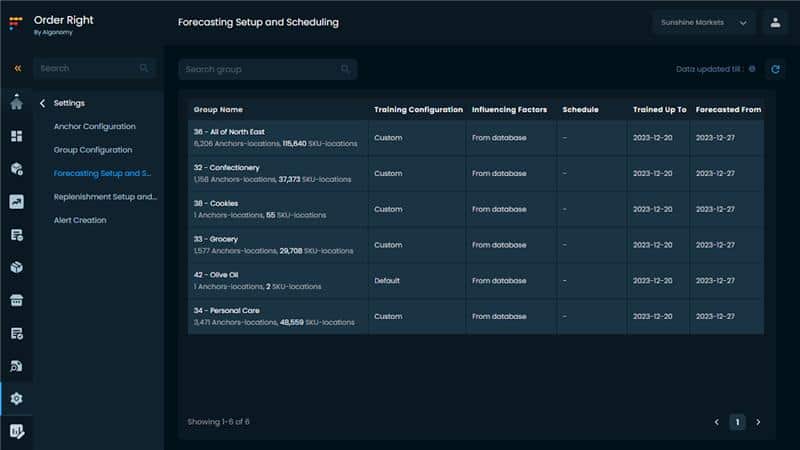
Now, the forecasts for all the anchors across all locations are displayed in a single dashboard, in different groups for centralized operation. Each forecasting group has multiple Anchors and each Anchor has several SKUs with locations.
For example, the following screenshot shows different groups and the first group has 6200+ anchors and 115000+ SKUs.
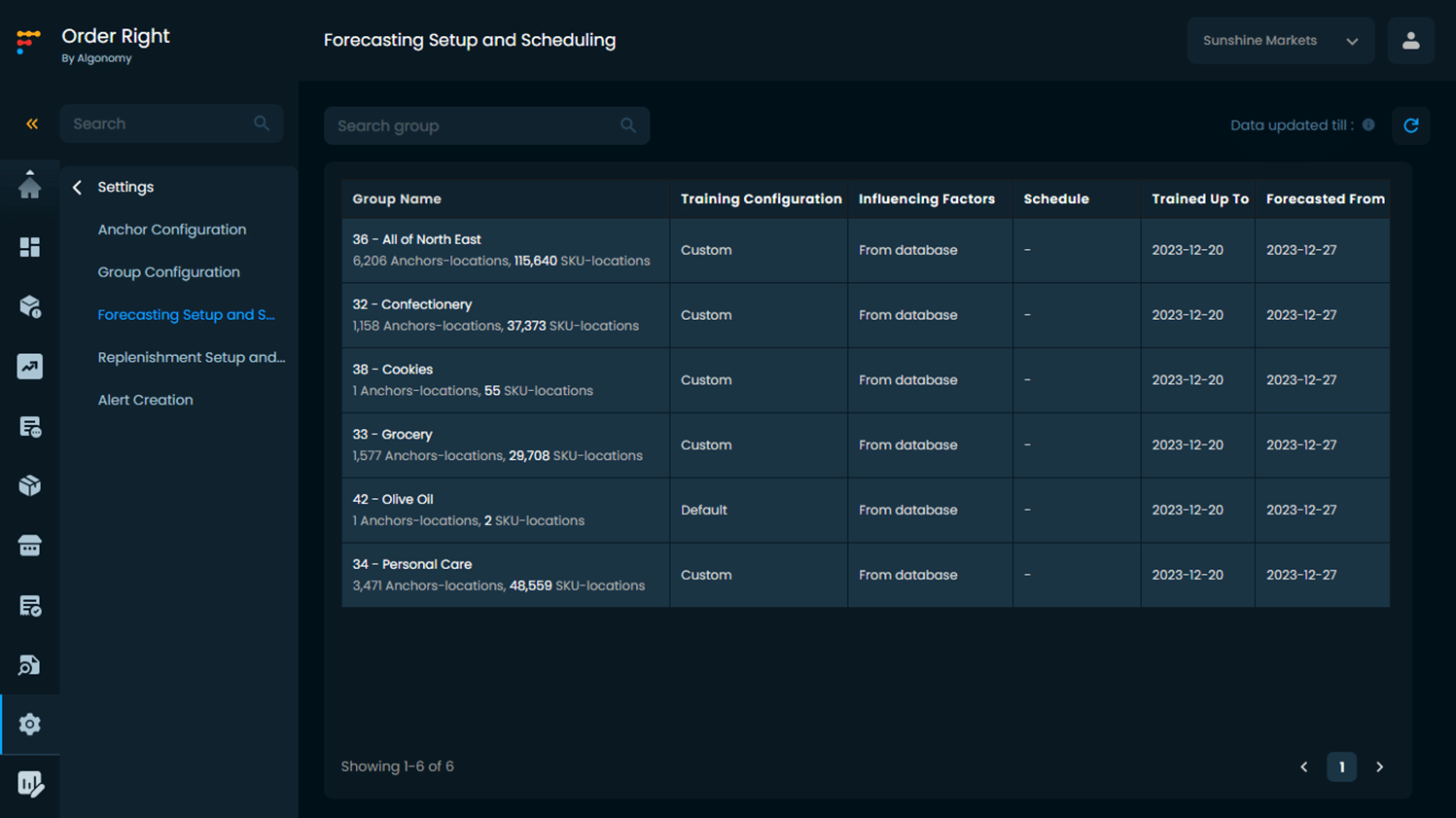
Order Right utilizes the anchor-level data which is more reliable, less sparse, and has minimal noise. Thus, retailers can generate highly accurate and reliable forecasts, and overcome the data challenges.
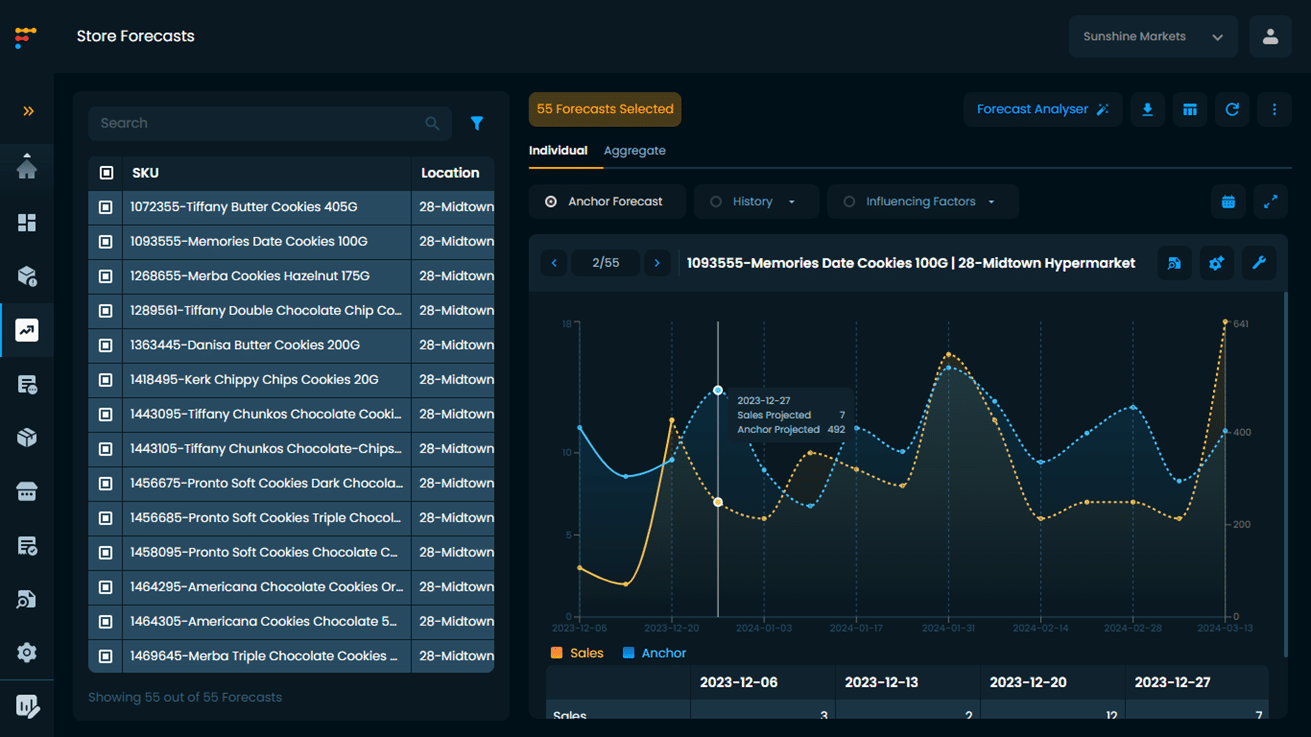
Given below, is an example of an anchor forecast and a SKU forecast for the Cookies category
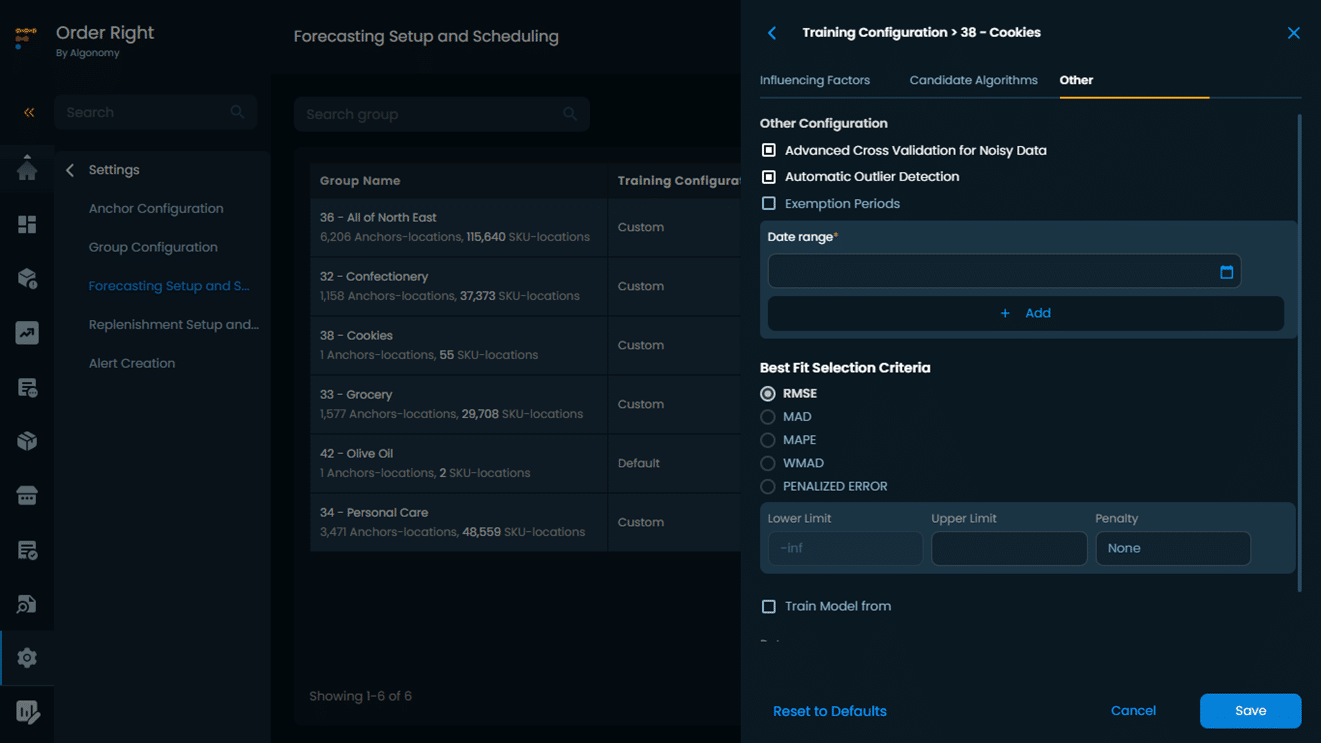
Additionally, OR, is equipped with many automatic outlier detection and imputation methods as part of its user configuration layer, which is offered as a standard built-in feature to all the users. These advanced capabilities enable the user to navigate the data complexities seamlessly.
Here is a snapshot of an OR model configuration layer with Automatic Outlier Detection and Imputation and Advance Training/Testing Split Methodology for Noisy Data:
Order Right inherently understands the associated noise and sparseness in retail data, and doesn’t handle them as exceptions, unlike other demand planning and forecast modeling software.
It comes with a built-in robust AI-driven framework that tackles the inherent data challenges in retail, capturing demand and supply patterns at an ultra-granular level. By leveraging retail-tuned ML algorithms and a unique hierarchical forecasting technique, it streamlines planning across merchandising, supply chain, and operations, helping retailers unlock:
Let’s face it—customers nowadays expect deeper and relevant communication, not cookie-cutter-styled messaging across every channel.
Deliver a best-in-class customer experience, increase online sales, and drive operational efficiency at scale

AI-powered social proof that reads every context and serves what converts.

